.svg)
Defining the Crypto x AI Stack
The convergence of crypto and artificial intelligence represents a new frontier, redefining how resources, data, and models are created, distributed, and used. Crypto infrastructure can capitalize on market dynamics and unique technology to train superior models and, in turn, create a diverse and meaningful application layer atop this infrastructure.
This article explores the AI stack in the context of Web3, detailing opportunities and challenges across three layers: the commodity layer, the model layer, and the application layer.
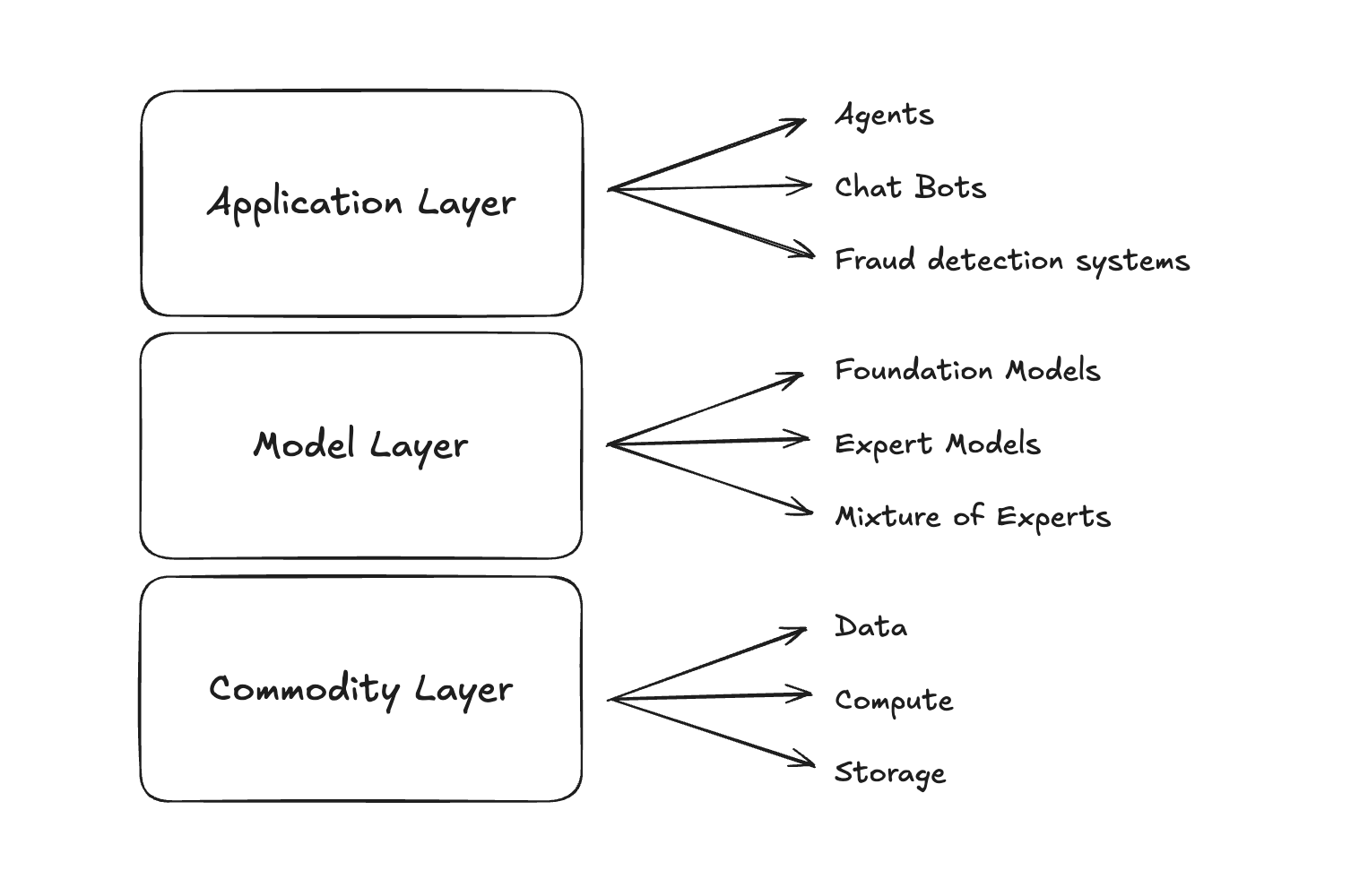
Commodity Layer
Decentralized physical infrastructure forms the backbone of AI compute, storage, and data solutions. Historically, Decentralized Physical Infrastructure Networks (DePINs) have struggled to compete with centralized providers on cost or ease of use. The emergence of AI introduces a new paradigm in which DePIN-driven solutions may leverage cryptographic primitives which synergize with existing protocols to unlock novel applications, allowing them to thrive in this new ecosystem.
Compute
The scarcity of GPUs introduced by the new demand for AI models is a critical catalyst for end-user adoption. Unlike traditional Web3 platforms that compete on cost and face hurdles like user experience and business development, decentralized AI compute markets address a unique, urgent demand where traditional options may not suffice. The exponentially growing compute demands of training large language models significantly outpace the supply offered by traditional marketplaces, driving users to look for other options. This differentiation has positioned decentralized compute networks as essential rather than merely cost-efficient alternatives.
Defensibility
Facilitation, Coordination, and Access
Significant inefficiencies exist in the production and consumption of compute, making compute more expensive for users, and leading to meaningful waste for producers. Blockchain integration with GPUs creates a unique, permissionless marketplace that facilitates seamless supply-side participation. GPUs–particularly during idle periods in research cycles–can be onboarded to offset capital expenditures and provide cost savings for smaller entities. The permissionless nature of these systems allows ephemeral GPU usage without requiring traditional onboarding processes like KYC, legal documentation, or billing agreements. This wasted capital and time is minimized so that marginal costs can approach zero, and the costs to users are more efficient. Price inefficiencies are also eliminated by removing walled garden services; decentralized compute marketplaces can offer a truly efficient marketplace because of their permissionless and democratized nature. This streamlined access significantly reduces costs for builders, hobbyists, and cost-conscious startups, enabling them to access compute resources on an ad hoc basis without large upfront commitments. Significant upticks in utilization on Akash as of late have shown promise that this market place is in demand:
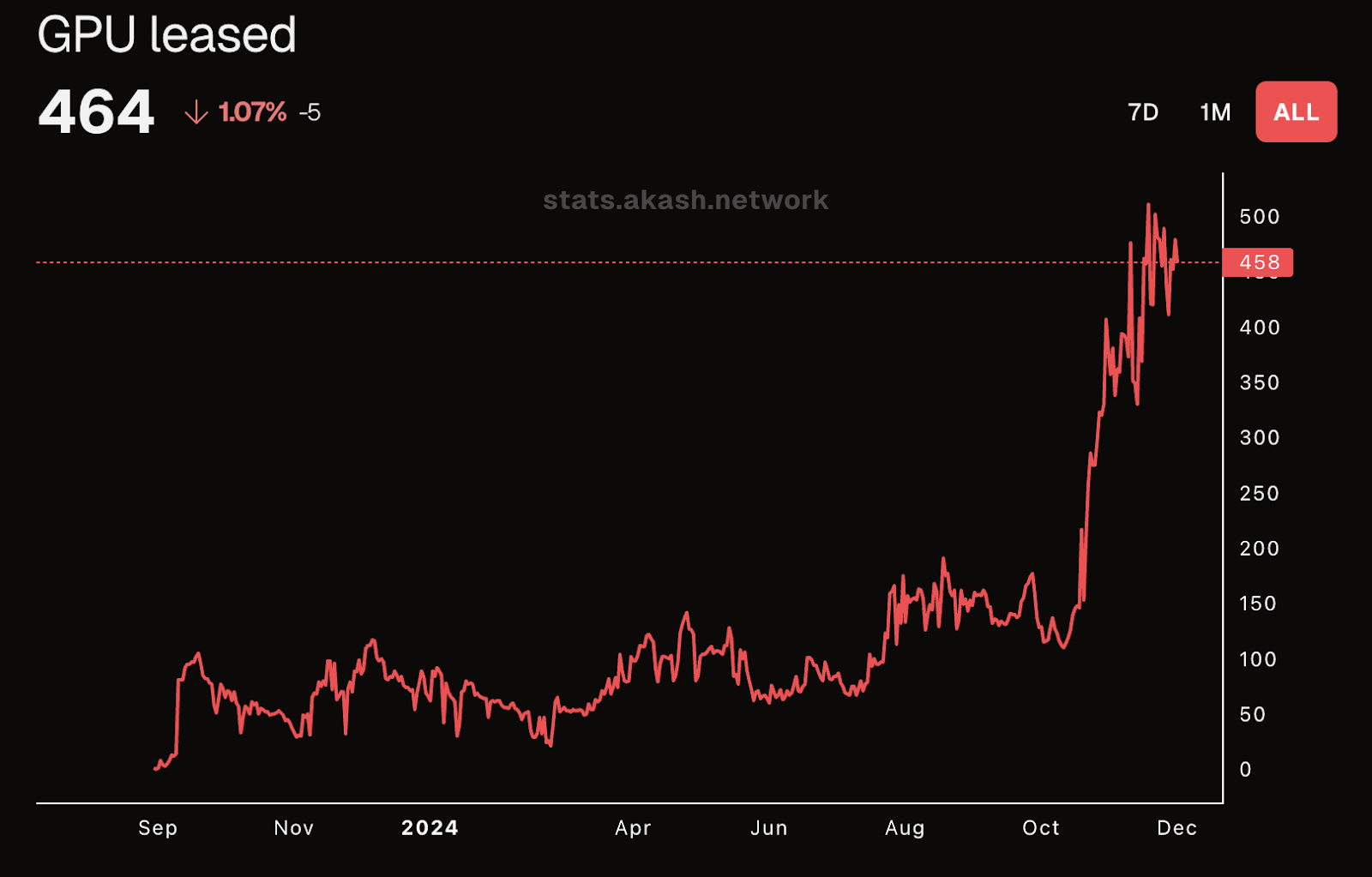
Akash GPU usage has grown steadily since launch in August ‘23, and has spiked significantly in late ‘24.
Distributed Training Techniques
Recent advances in distributed training have not only strengthened the viability of decentralized compute networks but could potentially unlock training at a scale that isn’t possible in a centralized way. Crypto’s ability to facilitate the aggregation of geographically distributed islands of compute affords the ability to scale larger than possible with centralized compute. We highlight some of the recent training advancements below:
-
DiLoCo: Distributed Low-Communication Training of Language Models
Google’s DiLoCo (and Prime Intellect’s OpenDiLoCo) introduces a training method requiring 500x less communication between nodes compared to traditional approaches. By synchronizing gradients only after several hundred batches, rather than after every batch, DiLoCo makes distributed environments more practical. Key advantages include:- Bandwidth Efficiency: Reduces communication overhead, making low-bandwidth distributed environments viable.
- Hardware Flexibility: Islands of GPUs can differ in hardware composition, provided that GPUs within an island are homogeneous.
- Robustness: Islands can drop in and out during training with minimal impact, as gradients are synced at checkpoints rather than continuously.
-
lo-fi: Distributed Fine-Tuning Without Communication
lo-fi builds on DiLoCo’s principles but applies to fine-tuning rather than training from scratch. It enables complete isolation of islands during tuning, with communication occurring only once—at the end of training. Each island trains on a unique shard of data, and the full model exists on each island. This approach is particularly effective for decentralized networks, as it allows isolated, efficient fine-tuning with benchmark-equivalent performance. -
DisTrO: Distributed Training Over-the-Internet
Nous Research’s DisTrO optimizes training by significantly reducing the bandwidth requirements for gradient synchronization, scaling bandwidth efficiency by up to 3000x during pretraining. Although smaller models struggle with DisTrO, larger models see no statistically significant degradation in loss, making it a breakthrough for enabling training over standard internet connections. This innovation dramatically expands the applicability of distributed training in decentralized environments.
These breakthroughs indicate that previous consensus assumptions were wrong: decentralized training can, in fact, compete with centralized techniques. While still in the early stages, more experimentation is needed, but the potential unlocks of these developments are exciting. Aggregating consumer compute for foundation model training, training across edge devices, training on private data, and training at scale that is larger than what could be accomplished in a single datacenter all seem within reach.
Inference
Inference markets will also be captured by distributed compute marketplaces. The aggregation of distributed compute will not only enable an efficient market for inference, but will also allow for optimizations around application speeds. Sourcing compute in different geographic locations will allow builders to minimize latency for users, improving application speeds. New developments in inference techniques have also enhanced the value of commercial-grade GPUs. One-bit quantization enables commercial GPUs to run state-of-the-art models at lower computational costs, making decentralized networks a viable solution for geographically distributed inference workloads. Decentralized marketplaces make it easier to deploy and scale these workloads dynamically, addressing regional demand variations more effectively than centralized systems.
Challenges
ML Workload Constraints: Machine learning workloads often involve moving large datasets between storage and memory in a synchronous manner. While the above distributed training techniques are promising, continued exploration and education will be needed to move developers to distributed training environments.
Service-Level Agreements (SLAs): Ensuring reliability across decentralized compute networks is a challenge. Verification of compute can be expensive: the added costs can nullify the value of decentralized training. Protocols are exploring reliability scoring systems, but consumer trust—whether directed at individual providers or the broader marketplace—remains a key concern.
User Experience (UX) and Crypto Friction: A seamless user experience is crucial. While incentivizing the use of protocol native-tokens should be the end goal, credit card payments are necessary for users unfamiliar with crypto to get started. Setting up a crypto wallet to source compute is prohibitive for many, and should be removed as a blocker. Today, while web3 products benefit from the use of native tokens to lower costs, frictions like poor UX and the need for crypto wallets generally prohibit mainstream adoption by end-users and developers alike.
Compute marketplaces are being coordinated both at significant scale and much more efficiently because of web3 mechanisms. By addressing previous training assumptions and experimenting with innovative techniques like DiLoCo, lo-fi, and DisTrO, decentralized compute networks are well-positioned to capitalize on the growing demand for AI resources. In doing so, these networks have the opportunity to provide unique value propositions that centralized systems cannot match due to the web2 infrastructure paradigm itself.
Data
The exponential growth of readily available digitalized data has made it the foundation of AI advancements, but quality data remains the bottleneck for training state-of-the-art models. A significant portion of high-quality data lies locked behind paywalls, security mechanisms, or exclusive access agreements, which fortify the moats of AI giants like Amazon, Google, and Microsoft. These incumbents have user data at an unmatched scale, leaving decentralized efforts struggling to compete. However, crypto incentives present a transformative opportunity to both generate fresh data and aggregate existing private data, unlocking a unique market that centralized entities can’t easily replicate.
The Opportunity for Incentivized Data Collection
Much of today’s data collection occurs on a small scale through web scraping, a method inherently limited by resources and reach. By introducing token-based rewards, blockchain protocols can entice widespread participation, enabling data collection networks capable of aggregating datasets rivaling those of incumbents. Projects like Grass, which organized data collection on Reddit, and Vana, which incentivizes large-scale scraping via Data Liquidity Pools, have demonstrated the potential of this approach.

Beyond traditional scraping, unique and organic data holds immense value. Personal, location-specific, or user-specific datasets offer unparalleled precision for AI fine-tuning. By incentivizing individuals to share these data, blockchain enables the creation of tailored datasets crucial for human-centered AI. Platforms such as Geodnet and Natix leverage edge devices to capture visual, kinematic, and geographic data–building robust, distributed datasets that centralized systems struggle to replicate.
Defensibility
Token incentives enable protocols to reward individuals for providing high-quality, unique data. This is antithetical to the walled-garden moat of centralized web2 providers that take this user data for “free” (reducing users to a commoditized product). Instead, this mechanism helps establish data as a scarce and valuable commodity, aligning user rewards with the increasing demand for premium datasets, empowering individuals with data agency.
Blockchain-based data collection thrives on distributed systems. Unlike centralized platforms, these networks aggregate data from diverse geographic locations and physical environments, providing richer, more representative datasets. By coordinating distributed data collection, protocols unlock a competitive edge which traditional AI firms cannot easily replicate.
Blockchain networks empower individuals to curate and share data directly from edge devices, removing intermediaries–as described in our piece on data curation networks. This not only creates cost efficiency but also ensures that contributors are fairly compensated. Projects like Dimo and Cudis are incentivizing users to capture data on edge devices and supply them for AI training datasets in exchange for rewards.
Challenges
Verification of Data Quality
Incentive-based systems are susceptible to exploitation. Reliable verification mechanisms are critical to prevent gamification issues in data collection networks. Zero-knowledge proofs offer a promising path forward, as zkTLS protocols like Reclaim and Opacity demonstrate, by enabling privacy-preserving validation of data authenticity.
Compliance and Legitimacy
With increased scrutiny on data privacy (see GDPR) and copyright violations, decentralized protocols can ensure data is collected ethically and with user consent, and that users reap the benefits of their data rights.
Decentralized solutions enable both the curation of net-new data and the collection of existing private data, while simultaneously granting individuals agency over their data. These mechanisms provide the decentralized AI stack with a critical differentiator over web2 solutions–granting access to otherwise unattainable data with the potential to unlock unique models and improve model quality downstream.
Model Layer
The model layer is the integration of raw digital commodities with machine learning models which serves as the infrastructure for AI applications. Within web3, the model layer offers exciting potential for innovation, particularly in the domain of generative AI. Broadly, the model layer can be broken down into two categories: foundation models and expert models.
Foundation models are massive, often multimodal, systems trained to generate outputs based on learned patterns. These models, such as GPT-4, possess incredible breadth of knowledge but often lack the depth required for highly specialized tasks.
Expert models, by contrast, are fine-tuned for specific use cases. They excel in depth and precision but do not have the general reasoning and fluency of their foundation model counterparts. They can be thought of more like utility tools rather than general purpose machines.
The Role of the Model Layer in Web3
The model layer in web3 has important distinctions from its web2 analog. Blockchains – through their native tokens – offer two key advantages. They allow for democratized access to GPUs and other resources, and enable users with data agency. In conjunction, these features create a mechanism for the proliferation of a diverse model ecosystem. The democratization of GPU ownership and access via tokenization in turn democratizes model creation and ownership. Data agency allows the creation of rich datasets that enable the creation of unique models. The combination of these mechanisms enables a diverse model ecosystem to flourish, and also allows the democratization of these models in a permissionless manner.
Crypto incentives can drive the creation and aggregation of quality models for different use cases. The technical knowledge, data requirements, and compute costs required to perform a fine-tuning run are significantly less demanding than what is required to train a foundation model. This opens the door for model marketplaces, where anyone can contribute models to specific verticals. Bittensor aims to create a diverse supply of models in an adversarial environment that allows builders optionality and ever-improving models for their applications.
Fractional model ownership introduces a novel way to distribute ownership. Models can be fractionalized based on contributions, such as supplying data or training resources. Tokenized ownership aligns incentives, as contributors are financially invested in a model’s success. Ora has pioneered the concept of Initial Model Offerings (IMOs), creating a more democratized approach to AI model ownership. Other projects, such as Pond, are leveraging blockchain data to train graph neural networks (GNNs). GNNs have myriad use cases. These models enable predictive applications tailored for onchain activities, such as fraud detection, trading strategies, and more. The combination of blockchain and model tokenization is a fundamental step toward unlocking this panacea of downstream applications and cannot be understated.
Additionally, blockchain technology can coordinate an open marketplace for model creation and hosting. Today, a small group of companies dominate model training and deployment, leaving end-users subject to their decisions, with no recourse. Building on top of centralized APIs poses risks; companies can swap models and weights and ruin downstream applications, as described by Adriano Caloiaro. Crypto marketplaces can decentralize this control, enabling individuals and organizations to access models without intermediaries. Projects like Bittensor and Ritual are working to create the infrastructure layer to host these decentralized models.
The robustness and censorship-resistance of access is another critical factor. As AI becomes integral to society, monopolized access to quality models could pose risks. Censorship has proliferated in tech of late, and will be easy for governments to enact given a monopolized AI landscape. Model diversity will suffer, and the lack of competition will stifle progress. The decentralized coordination enabled by blockchain can ensure that model access remains open, much like the early internet remained free and accessible due to open-source protocols.
Challenges
Despite its promise, the model layer in web3 faces significant hurdles.
The inability to keep up with centralized players is one concern. State-of-the-art models will likely continue to emerge from well-funded private companies capable of absorbing the high costs of foundation model training. Decentralized training is advancing rapidly, and the breakthroughs addressed above can help close the gap between decentralized players and incumbents. Access to private data and amassing more compute through decentralized means will provide an edge to web solutions.
The cold start problem is another challenge. Inference marketplaces rely on the availability of quality models and willing end-users. Without a robust ecosystem of well-trained models, it’s difficult to attract end-users to pay for services—and without paying users, developers may not host and train quality models.
Opportunities for the Future
The concept of fractionalized model ownership holds significant promise. This approach incentivizes individuals to provide high-quality, unique data in exchange for ownership stakes in the models their data helps to create. However, verifying the quality and impact of individual data contributions remains a challenge.
Meta’s work on influence functions offers a potential solution, as it enables the quantification of how much a specific data contribution improves a model. While still experimental, this approach aligns incentives effectively, encouraging users to submit quality or private data–providing a necessary advantage to models trained on crypto-incentivized data.
Importantly, the model layer will create robust and diverse rails for applications to flourish. Below are a few examples of web3 infrastructure solutions that can bring unique utility to application builders:
Meta’s work on influence functions offers a potential solution, as it enables the quantification of how much a specific data contribution improves a model. While still experimental, this approach aligns incentives effectively, encouraging users to submit valuable data.Importantly, the model layer will create robust and diverse rails for applications to flourish. Below are a few examples of web3 infrastructure solutions that can bring unique utility to application builders:
Application Layer
The application layer in decentralized AI can be broadly understood as the interface through which end users interact with AI. It is the tangible manifestation of a complex decentralized infrastructure (data, compute, and models) with practical, accessible products. Applications in this layer can range from AI agents operating locally to sophisticated systems leveraging distributed inference networks. This is the layer that the end-user experiences–whether it’s interacting with an AI Agent like Luna posting on X, or chatting with a distributed backend of models on Corcel.io.
The Flourishing Application Layer
Autonomous agents represent a rapidly growing segment of the application layer. Protocols like Virtuals enable the creation of community-owned agents, where anyone can deploy an agent and mint ERC-20 tokens linked to its revenue. These agents generate income through pay-for-inference microtransactions, giving token holders a stake in the agent’s success. With persistent memory, agents can exist across platforms like X, TikTok, Roblox, and others, evolving beyond novelty into utility-driven roles.
Projects like AI16z, an AI-agent DAO, allow developers all the tools to create and launch their own agents. The DAO captures revenue through incentive programs, encouraging developers to share tokens in exchange for community support. The success of these application layer projects, however, relies heavily on the infrastructure layer, as crypto’s microtransaction capabilities make it uniquely suited for agent-to-agent and agent-to-human transactions.

Agents have captured significant attention of late. One prominent agent, Zerebro, autonomously launched an NFT collection on solana. Image from Magic Eden.
Blockchains afford agents operational parity to humans, which doesn’t exist in traditional finance. There is no KYC or “proof-of-humanity” onchain, granting agents equal rights to humans and allowing them access to capital. This allows autonomous transacting onchain, managing funds (as seen with Sekoia), and serving as personal onchain assistants. This unique potential makes crypto ecosystems a natural home for autonomous agents.
The value of the web3 application layer capitalizes on the decentralized foundation of both the commodity layer and the model layer. By establishing a free, permissionless, and censorship-resistant marketplace for models, web3 applications enjoy significant advantages over web2 counterparts. Said differently: If web2 is checkers, web3 is chess–a semantically more complex and rich universe with more degrees of freedom. For example, applications can capture the benefits of diverse backends of constantly evolving models produced by a diverse set of engineers and data, as seen on Bittensor subnets like Bitmind. Chat projects like Venice AI guarantee data privacy in ways that web2 companies do not.
Blockchain technology also excels in aggregating diverse models via crypto incentives to create “mixture of experts” architectures. The ability to aggregate models like Bittensor is attempting to do can unlock greater intelligence at cheaper costs than possible with foundation models. This crypto-incentivized ecosystem of models and hardware forms the backbone for applications that can achieve unparalleled quality and functionality.
Unique Value Proposition of the Application Layer in Web3
The application layer represents the culmination of decentralized AI efforts, offering users tangible benefits through privacy, resilience, and state-of-the-art models. As this layer continues to mature, it will establish itself as the primary interface for mainstream adoption of AI technologies. The ability to leverage different application infrastructure architectures will enable app builders more freedom, which will result in a blockchain-powered AI ecosystem that is unrivaled by centralized AI. Unlike centralized AI systems, which often rely on opaque algorithms and centralized data control, the decentralized application layer empowers users to interact with AI in ways that prioritize transparency and autonomy. By utilizing decentralized networks, application builders can provide solutions that are resistant to censorship, ensure ownership of data and outputs, and deliver AI functionality that is free from the constraints of centralized gatekeepers. These qualities make the application layer a critical driver for mainstream adoption of decentralized AI technologies.
The ability to leverage diverse, decentralized infrastructures—ranging from blockchain-integrated models to hardware incentives—offers a unique sandbox for experimentation and growth. Decentralized applications capture expertise from diverse sources, creating systems that surpass the limitations of monolithic AI platforms, unlocking greater intelligence, efficiency, and adaptability. A decentralized application layer, comprised of a decentralized foundation, is the cornerstone of AI’s future.
The Revolution Will Not Be Centralized
AI will not be centralized. The decentralized path not only leads to better technical outcomes but better outcomes for humanity. A rapidly growing group of builders is championing the AI revolution in web3, and fighting to ensure that both the technology and regulatory races are won by our industry.
From a technical standpoint, blockchain enables a plethora of infrastructure opportunities that remove limitations from application builders. Decentralized applications powered by crypto-incentivized data will enjoy a defensible moat in AI, ensuring not just continuity of service but richer model quality as well. Increased model diversity coupled with unique data access will guarantee improved model quality in terms of breadth and intelligence. This will encourage developers to choose blockchain solutions, welcoming a diverse and expansive sea of applications powered by our industry.
Beyond technical benefits, blockchain eliminates reliance on centralized APIs, which can revoke access under regulatory pressure or due to commercial considerations. Data agency can be afforded to all humans through crypto incentives, and cutting-edge AI models can have democratized accessibility and user ownership through tokenization. A world in which AI is controlled by a few private corporations and governments does not inspire comfort; blockchain-powered AI solutions will prevent that.
The future of AI is made brighter by the integration of blockchain technology. Crypto’s ability to incentivize the curation of private data for training, facilitate distributed training across crypto-incentivized GPU marketplaces, and provide diverse infrastructure architectures for applications to capture end user value will fuel this integration over the next decade. The layers of the blockchain AI stack hold significant advantages over an AI stack absent these features, and will solidify blockchain’s place in the world of tech.
Disclaimer: Plaintext Capital holds positions in some of the mentioned projects at the time of writing.